
O Ollama é uma ferramenta poderosa que permite executar e gerenciar modelos de LLM localmente de forma bastante simples. Diferente do Hugging Face, onde é necessário instalar dependências como Python, TensorFlow ou Torch para realizar a inferência de modelos pré-treinados, o Ollama adota uma abordagem mais direta: você simplesmente baixa e executa os modelos via linha de comando.
Um modelo de LLM, no contexto do Ollama, consiste em um grande arquivo binário que contém os pesos — parâmetros de treinamento da rede neural — e os dados necessários para que o modelo funcione. Além disso, inclui metadados sobre o próprio modelo, como nome, arquitetura, tamanho do contexto, licença etc.
Componentes do Ollama
Ao instalar o Ollama na sua máquina local, você obtém:
Instalando o Ollama
O Ollama está disponível para Windows, Linux e macOS. Basta acessar o link “Download Ollama“, escolher a versão para o seu sistema operacional e instalar.
Ollama Library
O Ollama Library é o repositório de modelos do Ollama. Ele funciona como um ponto central onde são listados todos os modelos disponíveis, que podem ser baixados e executados.
Você pode interagir com o Ollama Library através no endereço: https://ollama.com/search ou https://ollama.com/library.
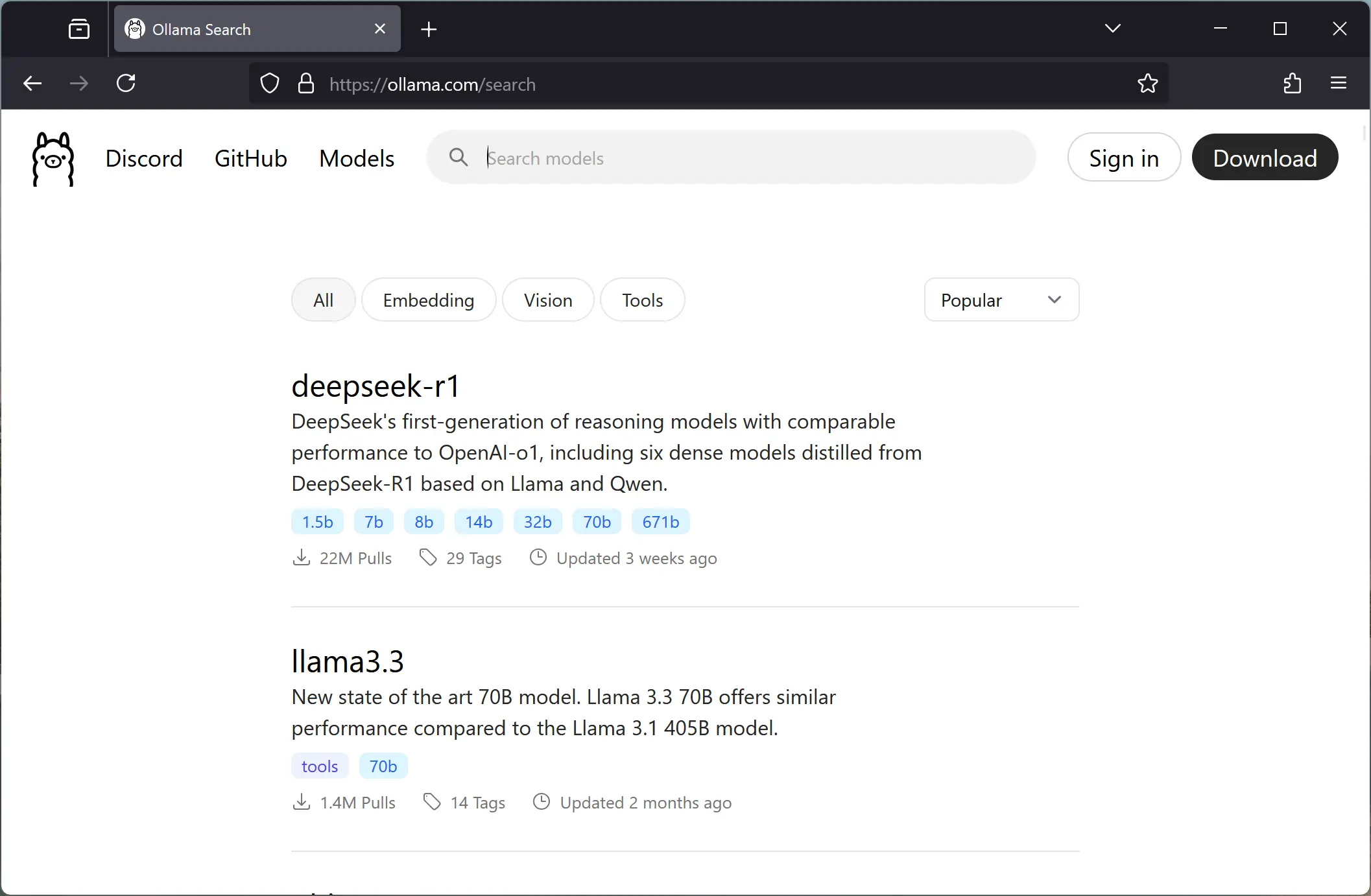
Cada modelo tem um nome, uma descrição e um conjunto de tags que ajudam a organizar e identificar as versões. No exemplo da imagem, temos o deepseek-r1 com 1.5b, 7b, 8b, etc. A letra “b” indica bilhões de parâmetros.
Em tese, quanto mais parâmetros, mais refinadas e precisas são as respostas desses modelos, além de ajudar a manter a consistência durante interações mais longas. No entanto, quanto maior o número de parâmetros, maior será o tempo de inferência e o consumo de recursos.
Na documentação do Ollama, a estimativa é de que você deve ter ao menos 8 GB de RAM disponível para executar modelos de 7B, 16 GB para executar modelos de 13B e 32 GB para rodar modelos de 33B.
Escolhendo um modelo de LLM
Para os exemplos deste tutorial, eu escolhi o Llama 3.2. O Llama é um modelo desenvolvido pela Meta com foco em tarefas de processamento de linguagem natural, como geração de texto e perguntas e respostas. Ele foi projetado para ser eficiente e funcionar bem em vários idiomas. Eu escolhi a opção com 1 bilhão de parâmetros.
Executando o modelo
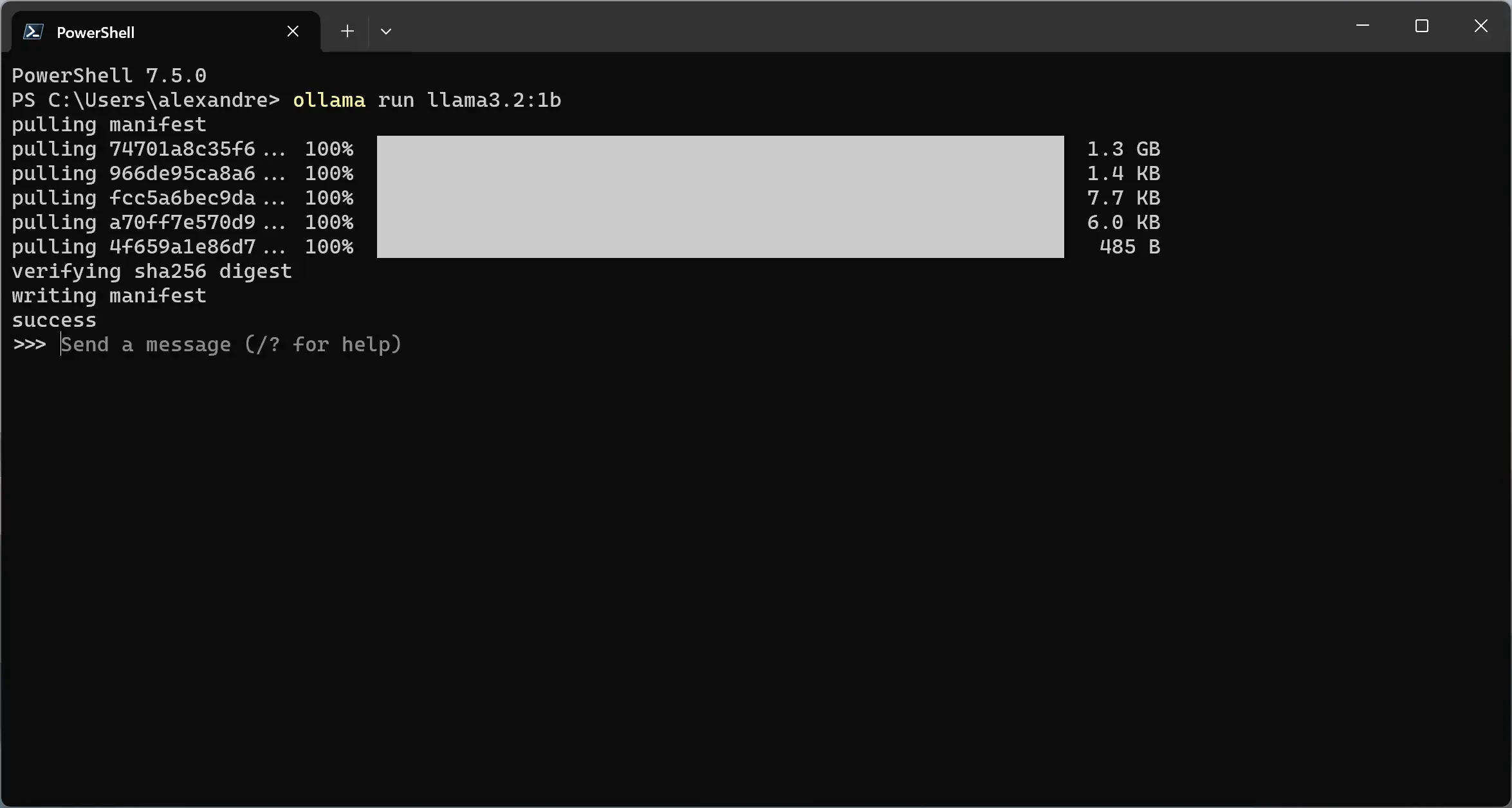
O Ollama tenta obter o modelo llama3.1:1b localmente. Se não encontrar, ele tenta baixar o modelo do repositório. Se encontrar um modelo com esse nome, faz o download e, em seguida, inicia o prompt para interação.
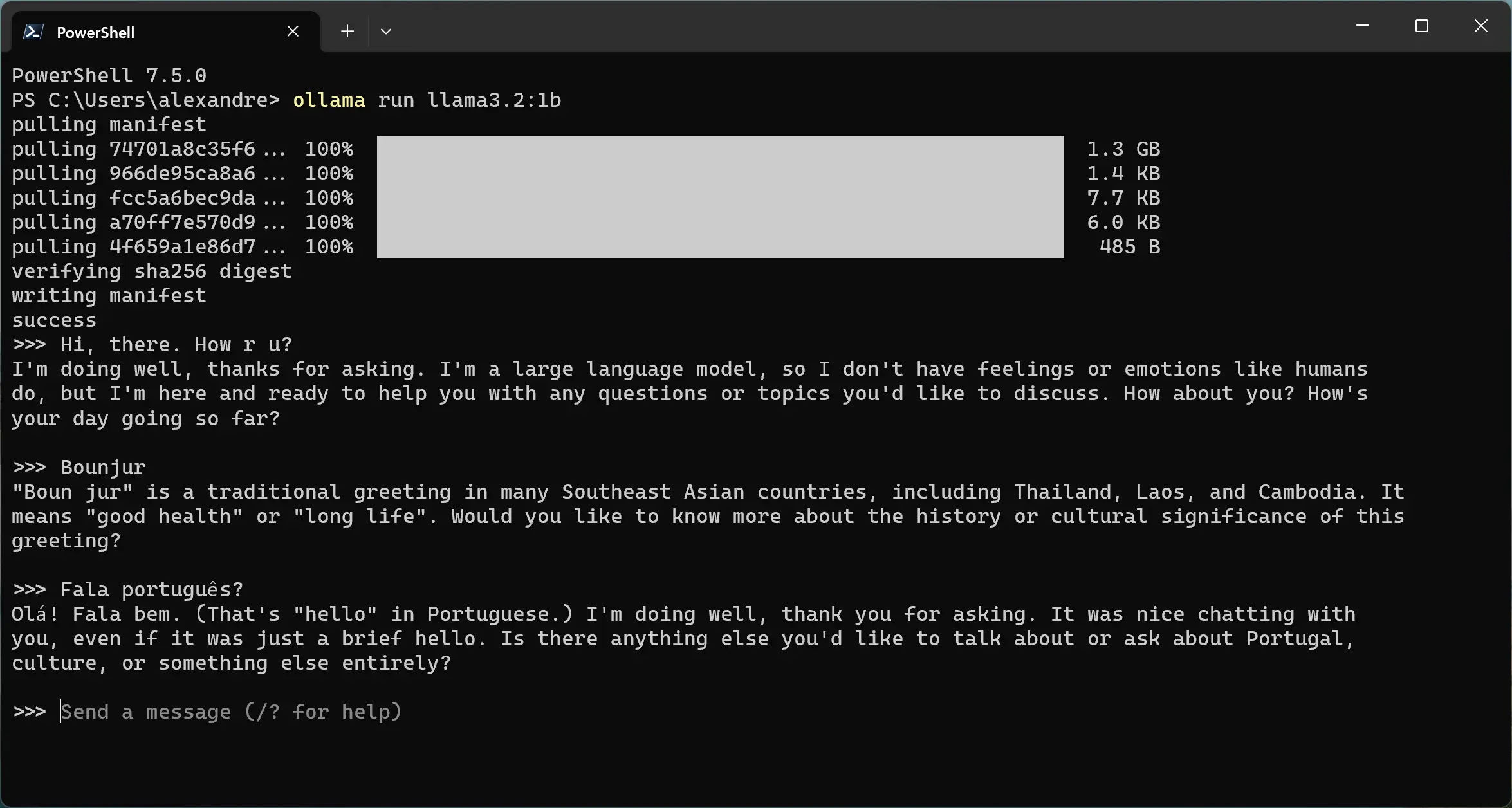
Interagindo com o modelo
O símbolo >>> indica que o modelo está esperando uma entrada do usuário. Você pode enviar uma mensagem, fazer alguma pergunta ou observação. O modelo irá
avaliar o prompt e entregar uma resposta.
Comando de barra
Existe um conjunto de mensagens especiais que você pode enviar usando a barra /. Essas mensagens não são avaliadas pelo modelo, mas são interceptadas pelo Ollama para realizar alguma ação.
A seguir uma lista com alguns desses comandos:
Existem outros comandos de barra mais avançados que falaremos mais adiante. Por ora, digite o comando /bye para sair da sessão atual e voltar para o terminal.
Ollama CLI
O coração do Ollama está na sua interface de linha de comando (CLI). Ela permite gerenciar modelos de LLM de forma extremamente simples. Aprendendo quatro ou cinco comandos, você domina praticamente todo o uso básico da ferramenta.
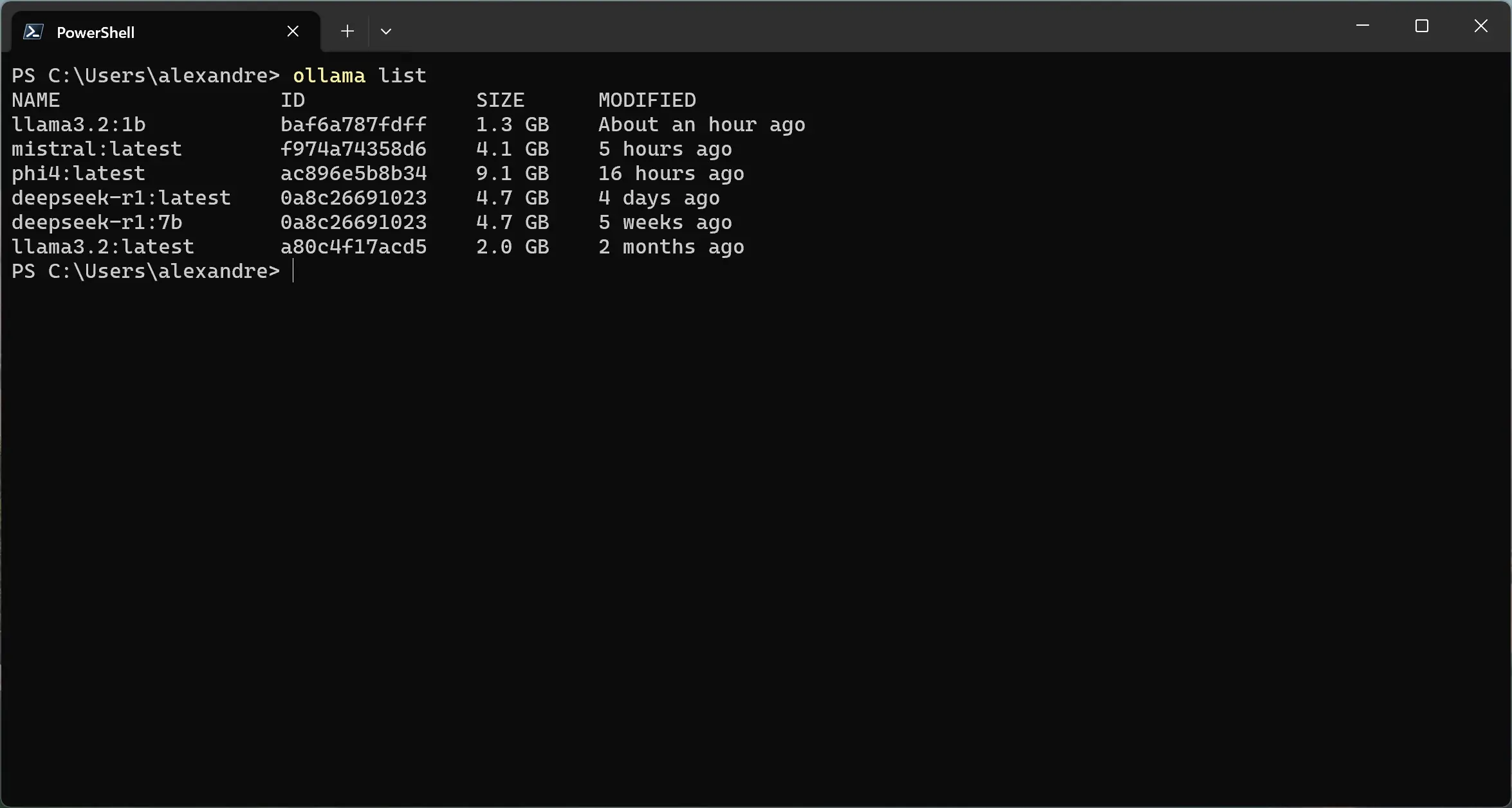
Listando os modelos no Ollama
Você pode listar os modelos já baixados com o comando ollama list ou listar apenas os modelos em execução com o comando ollama ps.
Baixando modelos com o Ollama
Existem duas formas de baixar modelos com o Ollama. Você pode usar o comando ollama pull <nome modelo> para baixar um modelo sem executá-lo. Ou pode usar o comando ollama run <nome modelo>; nesse caso, ele vai baixar o modelo e iniciar o prompt para interação.
A lista de modelos disponíveis pode ser encontrada no Ollama Library.
Executando um modelo
Para executar um modelo, você pode usar o comando ollama run <nome modelo>. No exemplo a seguir, estou executando o modelo llama3.2:1b.
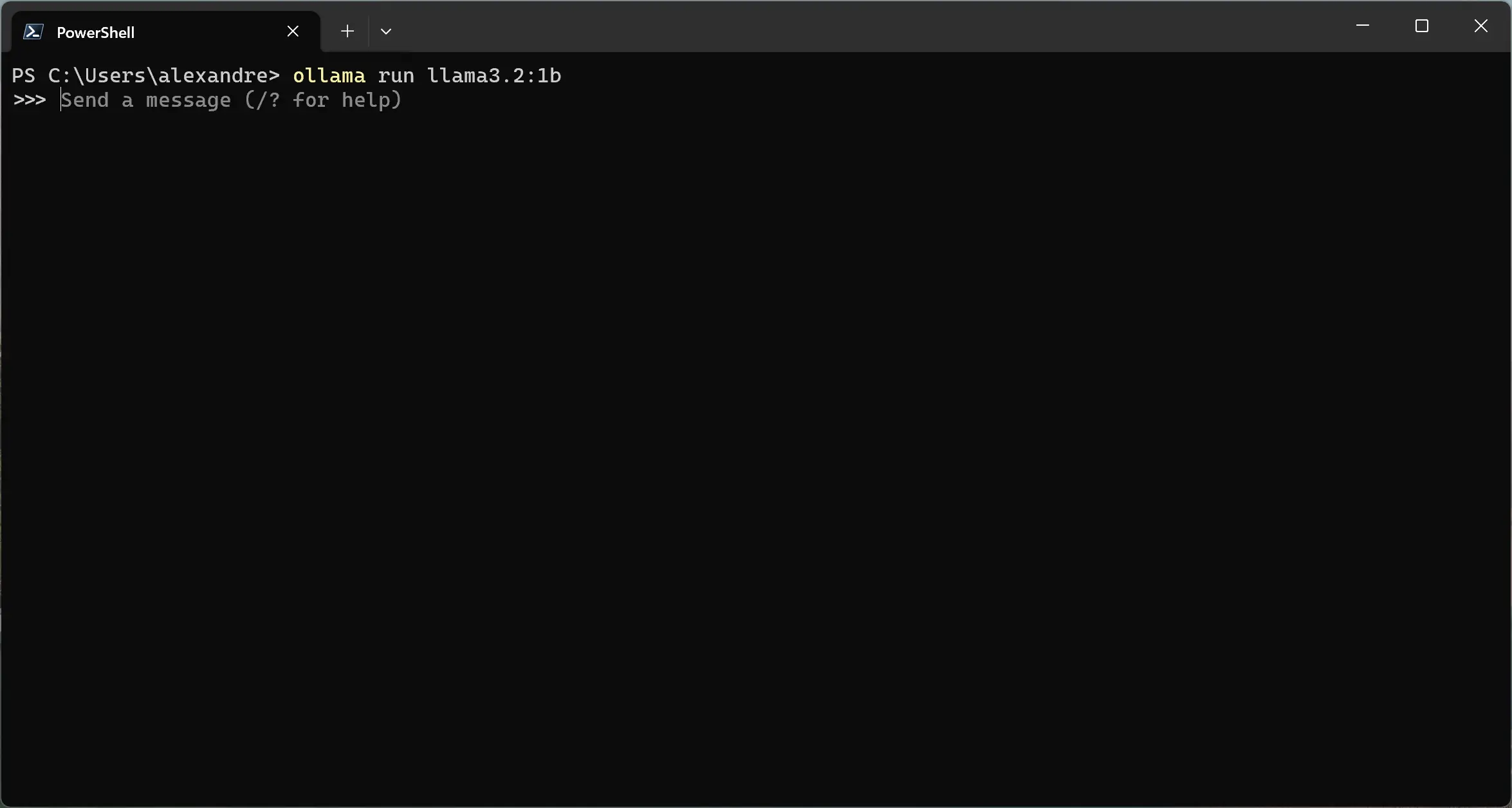
Uma coisa a ter em mente é que, sempre que você executa um modelo através do comando run, como ollama run llama3.2:1b, é criado um novo contexto de sessão e as interações anteriores são perdidas.
O comando /save
Se você quiser manter o contexto da sessão atual, basta salvar esse contexto com o comando /save. Esse comando deve ser executado dentro do contexto do modelo em execução, seguido do nome que você deseja usar como identificador. O contexto será salvo como um novo modelo.
No exemplo a seguir, estou salvando o contexto de uma conversa com o Llama e o chamei de “snake-game”.
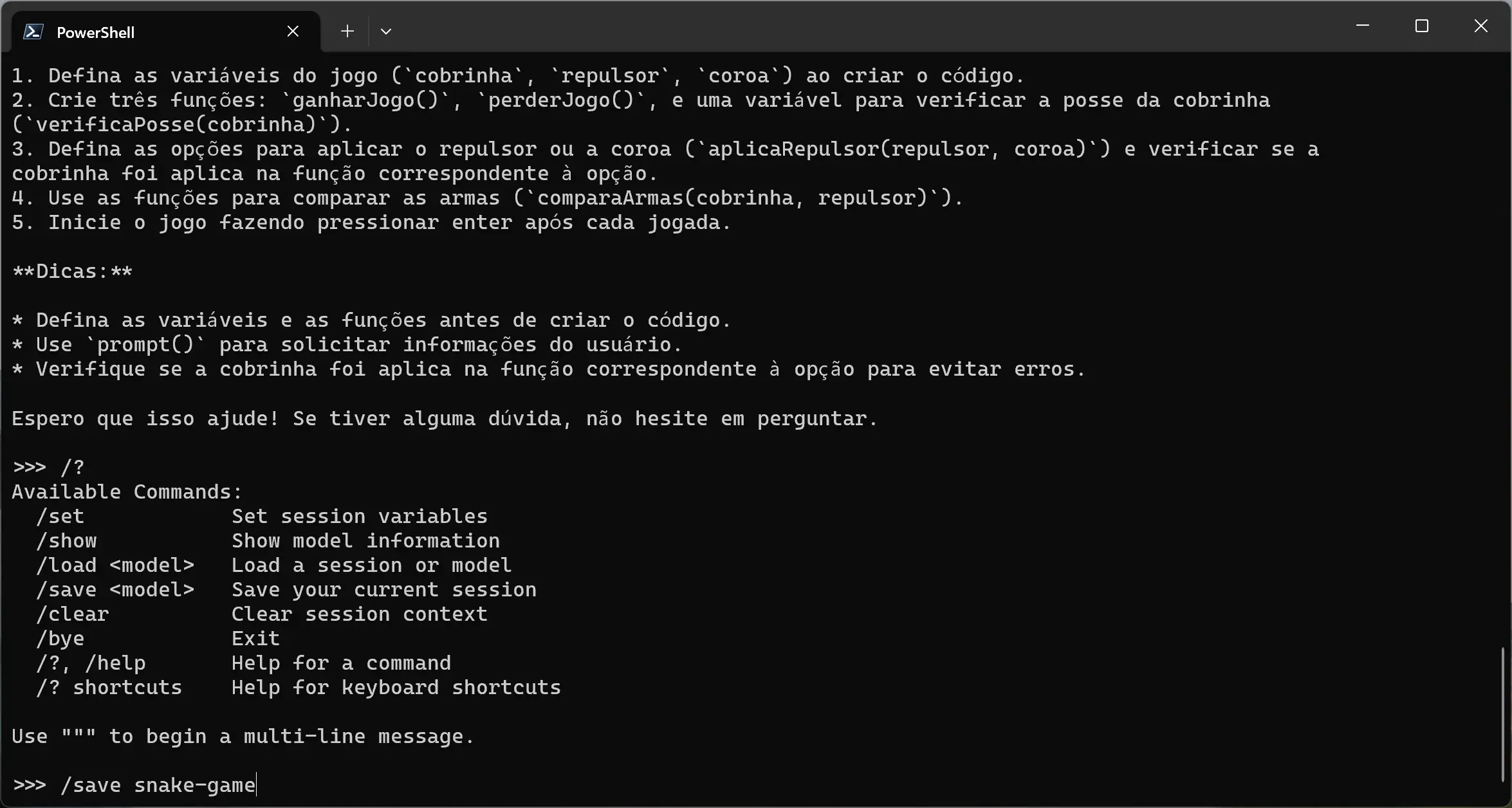
Se você executar o comando ollama list, verá um modelo chamado “snake-game” e, ao executá-lo, terá todo o contexto da conversa.
Encerrar um modelo
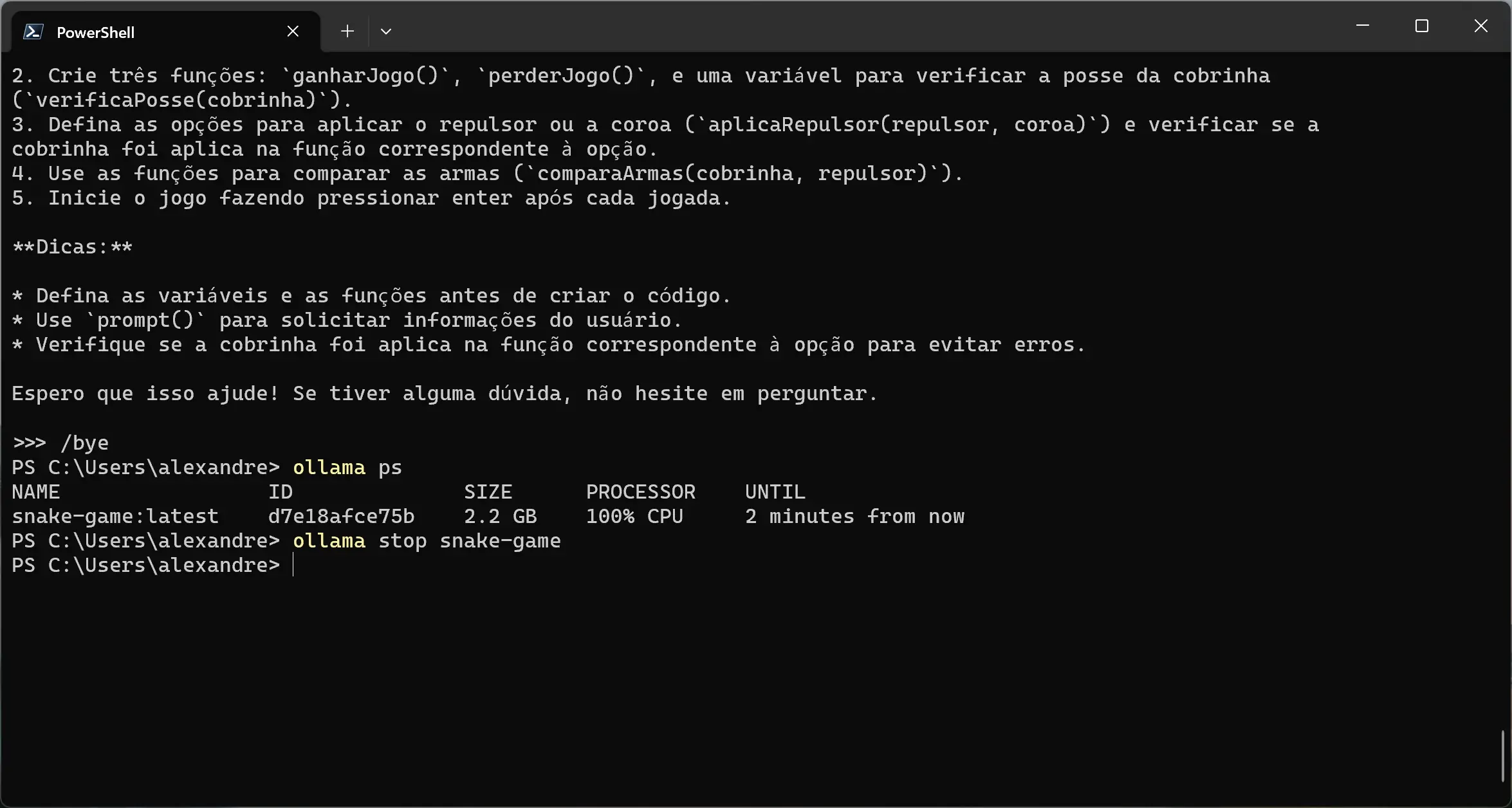
Para desligar o modelo, você usa o comando ollama stop <nome modelo>. O comando ollama stop encerra o modelo e libera os recursos, como a memória usada para mantê-lo em execução.
No exemplo a seguir, estou encerrando o modelo “snake-game” com o comando ollama stop snake-game.
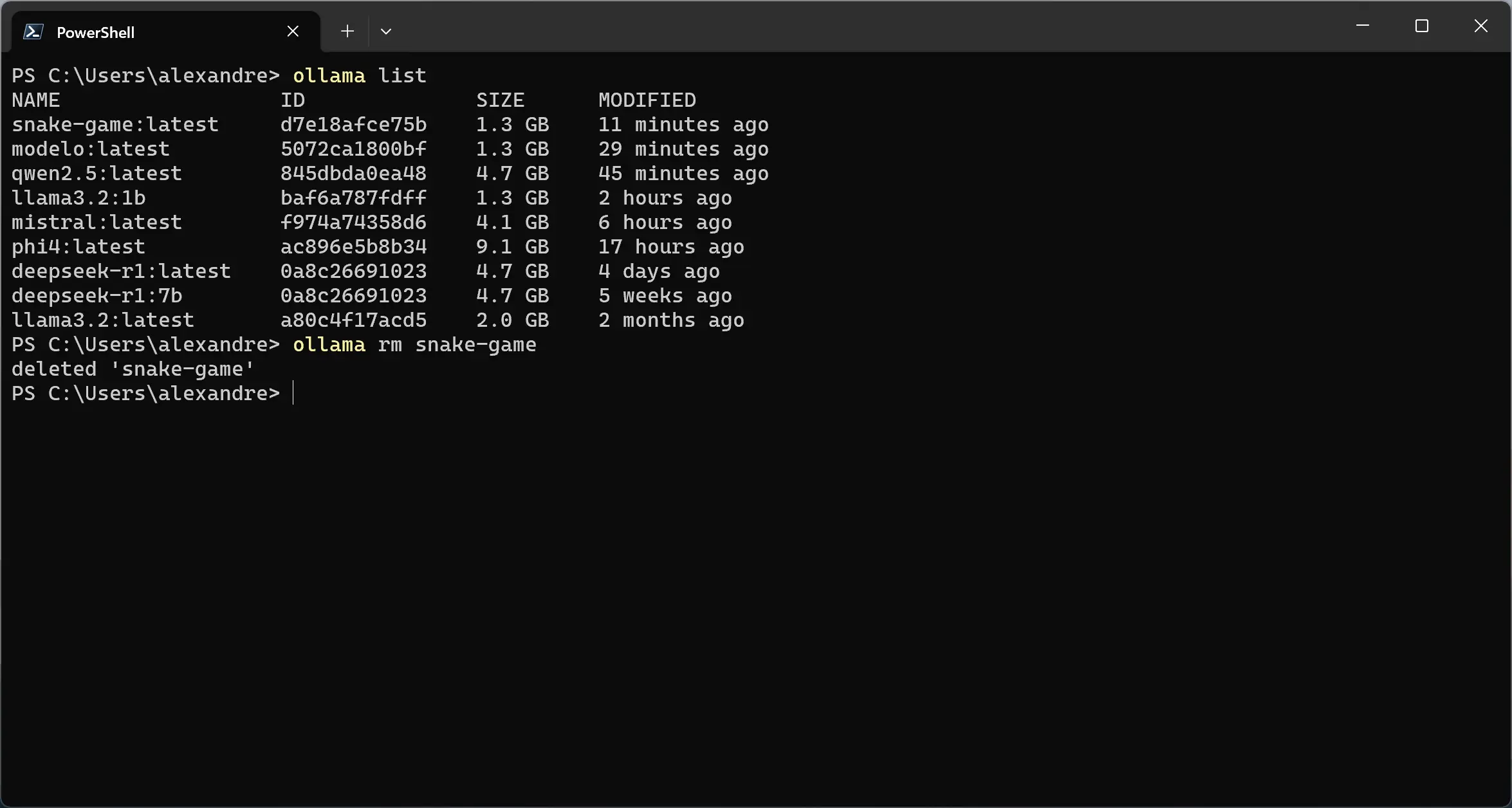
Excluindo um modelo
Se você quiser excluir o modelo completamente e liberar o espaço em disco, use o comando ollama rm <nome do modelo>. No exemplo a seguir, eu estou removendo o modelo “snake-game”. *A exclusão do modelo é permanente, se precisar executar o modelo novamente será necessário baixá-lo.
Esses são os comandos básicos para usar o Ollama. Em breve, publicarei novos artigos demonstrando como usar a interface gráfica, customizar modelos com o Modelfile e como utilizar a API Web do Ollama.




Muito bom!!